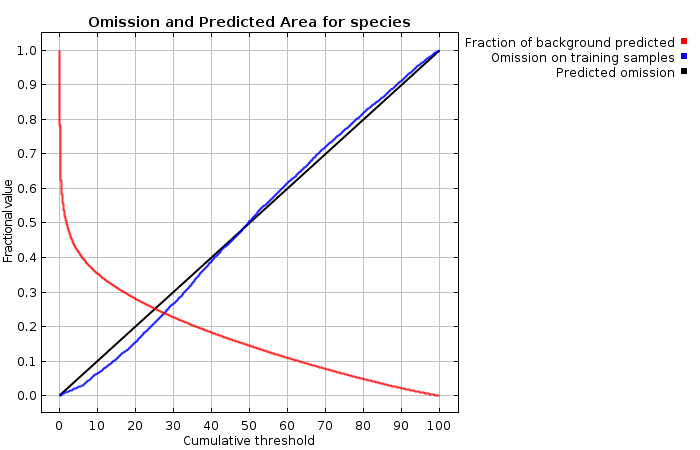
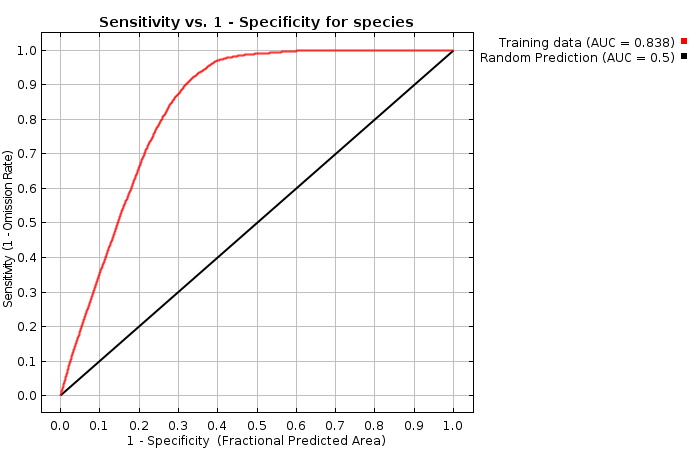
| Cumulative threshold | Cloglog threshold | Description | Fractional predicted area | Training omission rate |
|---|
| 1.000 | 0.061 | Fixed cumulative value 1 | 0.541 | 0.007 |
| 5.000 | 0.234 | Fixed cumulative value 5 | 0.414 | 0.026 |
| 10.000 | 0.371 | Fixed cumulative value 10 | 0.353 | 0.065 |
| 0.026 | 0.003 | Minimum training presence | 0.747 | 0.000 |
| 14.150 | 0.453 | 10 percentile training presence | 0.319 | 0.100 |
| 27.434 | 0.581 | Equal training sensitivity and specificity | 0.239 | 0.239 |
| 10.818 | 0.386 | Maximum training sensitivity plus specificity | 0.345 | 0.070 |
| 2.056 | 0.107 | Balance training omission, predicted area and threshold value | 0.487 | 0.011 |
| 3.643 | 0.175 | Equate entropy of thresholded and original distributions | 0.440 | 0.018 |