Chapter 22 Simulating and analysing data from questionnaires
22.1 Introduction
The Likert scale is very commonly chosen for measuring the degree of agreement with statements in questionnaires. We can use the example of Likert scale data to look at a range of technical aspects regarding the way data is handled in R. The data collected from questionnaires is best handled using the approach used in relational data bases. At least three linked tables are usually needed.
Likert data can be analysed using a range of multivariate analyses. In this example we will look at latent factor analysis which is closely related to principal components analysis.
22.1.1 Packages used
## Load the packages
library(dplyr)
library(aqm)
library(ggplot2)
library(tidyr)
library(MASS)
library(psych)22.2 Simulating a single vector of Likert data
To simulate responses from the Likert scale with known expected proportions we can write a function that takes the number of simulated responses required and a vector of proportion responding in each class. The following chunk builds a function that will by default return 1000 responses, which in this case will tend to be positive.
rand_likert<-function(n=1000, p=c(1,2,3,5,10))
{
## Form a vector of responses
lscale<-c("Strongly disagree","Disagree","Neutral","Agree","Strongly agree")
## Sample 1000 times with replacement and unequal probability
lik<-sample(lscale,n,replace=TRUE,prob=p)
## Turn the response into an ordered factor
lik<-factor(lik,lscale,ordered=TRUE)
lik
}Notice that the function works in the following way ..
- The “lscale” object is a vector of categorical responses.
- The second command samples responses from this vector with a probability given by the numbers in a second vector. If this is not provided then all the values have an equal probability of being chosen. So we can simulate responses that tend to be positive by providing a vector with high values on the right hand side (as in the default for the function)
- The result of sampling is a character vector. We can form the character vector into an ordered factor by providing a list of values in order. The lscale vector is such a list, so the function returned an ordered factor.
The function has been included in the aqm package on the server.
# If working offf the server the aqm package can be installed by running
# devtools::install_github("dgolicher/aqm")22.2.1 Character vectors and factors
The example provides another opportunity to explain the difference between character vectors and factors. The function returns an ordered factor
q1<-rand_likert(100)
str(q1)## Ord.factor w/ 5 levels "Strongly disagree"<..: 5 5 4 2 5 2 2 4 4 5 ...The vector actually consists of numerical values between 1 and 5 with the factor levels as labels. If we coerce the factor to a character vector then the vector will just contains text.
q1<-as.character(q1)
str(q1)## chr [1:100] "Strongly agree" "Strongly agree" "Agree" "Disagree" ...It is important to be aware that if data held in the form of text is read into R from a data file using read.csv then R will silently coerce the character vector to a factor. This behaviour differs from that of the read_csv function in the readr package which keeps the data as a character vector unless other instructions are provided.
Notice that when we coerce a character vector for Likert scale text into a factor it will not automatically be in the order we would like. The default order will simply be the alphabetical order.
q1<-as.factor(q1)
str(q1)## Factor w/ 5 levels "Agree","Disagree",..: 4 4 1 2 4 2 2 1 1 4 ...levels(q1)## [1] "Agree" "Disagree" "Neutral"
## [4] "Strongly agree" "Strongly disagree"This is not what we want for analysis, as the factor is not in the right order.
To produce an ordered factor we need to look at the levels of the factor which are produced by default and then place them in a more logical order. This step requires a little care, as there is the possibility for errors if text has not been used consistently when scoring the results.
q1<-factor(q1,levels(q1)[c(5,2,3,1,4)],ordered=TRUE)
str(q1)## Ord.factor w/ 5 levels "Strongly disagree"<..: 5 5 4 2 5 2 2 4 4 5 ...22.3 Numerical vectors to Likert vectors
When collecting the real life data and capturing it in a spreadsheet the Likert scale may often be scored as numbers on a scale of 1 to 5. When the data is read into R the numbers will appear as integers. This can be changed
num_to_likert<-function(x){
lscale<-c("Strongly disagree","Disagree","Neutral","Agree","Strongly agree")
lik<-factor(x,1:5,ordered=TRUE)
levels(lik)<-lscale
lik
}
x<-sample(1:5, 10,replace=TRUE)
x## [1] 4 2 2 5 4 2 1 3 5 3num_to_likert(x)## [1] Agree Disagree Disagree Strongly agree
## [5] Agree Disagree Strongly disagree Neutral
## [9] Strongly agree Neutral
## 5 Levels: Strongly disagree < Disagree < Neutral < ... < Strongly agreeThe function can be applied to all the columns of a data frame read into R by using the mutate_all function in dplyr.
Notice that the inverse operation is very easy. Just coerce the vector to numeric.
as.numeric(x)## [1] 4 2 2 5 4 2 1 3 5 322.3.1 Forming a data frame
Let’s now simulate the responses of one thousand people to four questions. Notice that the first question takes the default vector of probabilities. The second question provokes more negative responses. The third question is more neutral and the final question has a “marmite” type response.
q1<-rand_likert()
q2<-rand_likert(p=c(4,3,1,1,1))
q3<-rand_likert(p=c(1,2,5,2,1))
q4<-rand_likert(p=c(5,1,1,1,4))
q5<- beta_likert(n=1000) ## Using the beta_likert explained later in the text
d<-data.frame(id=1:1000,q1,q2,q3,q4,q5)Looking at the raw data..
dt(d)This produces a wide data frame. This is likely to represent the way data were entered in a spreadsheet or other tabular data capturing software. It is not wrong in any way to represent data in this form. Some analyses do work on data in a wide format. One example would be to use base R to tabulate each response.
table(d$q1)##
## Strongly disagree Disagree Neutral Agree
## 52 99 133 221
## Strongly agree
## 495Or to use qqplot to produce a barplot for a single question
ggplot(d,aes(x=q2)) + geom_bar() +coord_flip()
However this can get very tedious and repetitive as we need to repeat the code for each question.
The four columns holding the responses to questions can be thought of as forming a matrix. A matrix is a rectangular data structure with two dimensions. The key characteristic of a data matrix is that all the values in the matrix are on the same scale. So a likert based matrix can only contain values from 1 to 5 or the associated text.
A true data frame would consist of only three columns. The id of the individual providing the response, a column holding the code for the question asked and a third column containing the response.
Providing the data that has either been simulated or read into R from a spreadsheet has a unique id as the first column then the data can be pivoted into a long format with the following code.
df<-pivot_longer(d, cols=-id,names_to="question",values_to = "response")
dt(df)Now we can tabulate all the data with just one string of commands.
df %>% group_by(question,response) %>% summarise(n=n()) %>% mutate(percent = round(100*n / sum(n),0)) -> tb
dt(tb)22.3.2 Adding question text
In order to collect real data the survey will be based on questions which may frequently consist of longish sentences. They may also be grouped by theme.
The easiest way to handle questionnaire data of this type is to use a relational data structure in which data corresponding to details on the question content are held in an additional table that can be linked to the responses and data on the individuals who provided the responses held in another table. The tables can then be linked together.
For example, the text of the questions used in the NSS survey of student satisfaction is included in the aqm package. When capturing your own survey data you should provide a similar table of data on each question. Notice that this avoids having to use long strings of text as headers in the table of Likert data that you import into R. Just use simple question indices as column headers if the data are in wide format in the spreadsheet, or a column with question id codes if the data are in long format.
data(nss_questions)
dt(nss_questions)22.3.3 Joining the two tables
Tables can be joined together very easily in R by using either the merge function in base R or the dplyr family of join functions. The latter approach is now the preferred one, although the results are exactly the same.
In order to merge two tables in a simple manner you must ensure that one AND ONLY ONE of the columns has the same name in each table and that the column contains data of the same form in both tables. ALWAYS CHECK VERY CAREFULLY BEFORE MERGING
If you inadvertently try to join tables which have several columns of the same name you would be telling R to form an object with the number of dimensions of the number of rows to the power of the number of shared column names. This could exceed the memory capacity and crash your R session, and is never what you actually want.
In this case the questions column holds characters representing the question number which are identical in each table. So the join works on both the raw data and on the derived table.
library(dplyr)
df<-inner_join(df,nss_questions)
tb<-inner_join(tb,nss_questions)22.3.4 Plotting the results
There are many different possible figures that could be used to display Likert data. The worst would be to use pie charts. Pie Charts are generally considered to be very poor figures. They can be produced in R but there is no default option in ggplots. A much better figure is a labelled barchart with the percentages placed on the top of the bars. This looks better when flipped horizontally. Notice that wherever possible you should aim to help the reader of a descriptive data analysis such as this to extract the raw data.
ggplot(data=tb,aes(x=response,y=percent,label=percent)) + facet_wrap('short_text') +
geom_bar(stat="identity") +
geom_label() + xlab("Response on Likert scale") +ylab("Percent of responses (n=500)") +
coord_flip()
#theme(axis.text.x = element_text(angle = 45, hjust = 1)) # Remove coord flip and comment if you want vertical bars with labels at the bottom.Another very good, more compact option is to use a stacked bar chart, again flipped horizontally to produce a shaded ribbon for each response.
ggplot(tb) +
aes(x = short_text, y = percent, fill = response, label=percent) +
geom_bar(stat="identity", width = 0.5)+
coord_flip() + xlab("Short description of question text") +ylab("Percent of responses (n=500)") +
geom_text(aes(label = percent), position = position_stack(vjust = 0.5)) +
scale_fill_manual(
values = colorRampPalette(
RColorBrewer::brewer.pal(n = 5, name = "RdBu"))(6),
guide = guide_legend(reverse = TRUE)) 
22.3.5 Grouping data
One way of getting around the well known poor statistical properties of raw Likert scale data is to pool questions. If three or more questions are asked on different aspects of the same topic the mean of the numerical values of the Likert scale can be taken as a measure of agreement. These responses will tend to follow an approximately Gaussian (Normal) distribution, as the Gaussian distribution arises as a result of addition of various factors acting independently. In this case the results are not actually independent but the general principle will still apply. However using this approach may involve making some arbitrary decisions regarding the grouping of questions.
As an illustration of how to apply this idea we can group the responses to individual questions on the Likert scale according to the groups in the NSS question table.
str(df)## tibble [5,000 × 6] (S3: tbl_df/tbl/data.frame)
## $ id : int [1:5000] 1 1 1 1 1 2 2 2 2 2 ...
## $ question : chr [1:5000] "q1" "q2" "q3" "q4" ...
## $ response : Ord.factor w/ 5 levels "Strongly disagree"<..: 1 1 3 5 2 3 2 3 1 3 ...
## $ text : chr [1:5000] "Staff are good at explaining things" "Staff have made the subject interesting" "The course is intellectually stimulating" "My course has challenged me to achieve my best work" ...
## $ short_text: chr [1:5000] "Well explained" "Interesting" "Stimulating" "Challenging" ...
## $ group : chr [1:5000] "teaching" "teaching" "teaching" "teaching" ...df %>% group_by(id,group) %>% summarise (score=mean(as.numeric(response))) -> mean_score
head(mean_score)## # A tibble: 6 x 3
## # Groups: id [3]
## id group score
## <int> <chr> <dbl>
## 1 1 learning 2
## 2 1 teaching 2.5
## 3 2 learning 3
## 4 2 teaching 2.25
## 5 3 learning 3
## 6 3 teaching 3.25The mean scores for a group of questions will tend to form a normal distribution. So conventional statistical techniques can be applied to such data. This is a very good way of getting around some of the issues with the ordinal likert scale.
mean_score %>% filter(group=="teaching") %>% ggplot(aes(x=score)) + geom_histogram()
22.4 Simulating responses that differ between subject specific variables
The questions asked about Likert scale data often consist of looking at differences in response which are related to other variables collected on subjects.
The data manipulation shown above is based on a simulated questionnaire consisting only of Likert responses. The data collected on the individual survey respondents will often be quite mixed. It may consist of factors, either ordered or unordered, numerical values, character vectors or yes/no binary responses. A real life survey may also contain free text. This can be analysed in R using a range of methods shown in a later chapter.
In order to organise your data neatly you need to aggregate all the Likert scale responses into one data table and all non Likert data into one (or possibly more than one) additional table which can be linked to the Likert responses through a common subect id. This will usually be anonymous. Only a person in possession of a table containing the actual name of the respondent can de-anonimise the data, and this can be stored separately from the rest of the data.
Let’s simulate two simple characteristics of subjects in a survey. Notice that the table representing characteristics of the subjects can be linked to their responses through the anonymous id column. This is common to both tables.
id<-1:1000
gender<-rep(c("Male","Female"),each=500)
age<-sample(18:50,1000,replace=TRUE)
subjects<-data.frame(id,gender,age)22.4.1 Using the beta distribution to simulate Likert data
The beta distribution is a continuous distribution which is bounded to lie between 0 and 1. Two parameters are used to define the form of the distribution, the shape and scale. This makes the distribution very flexible in form. It can easily represent “marmite” type patterns by setting certain combinations of shape and scale. However the parametrisation of a beta distribution is rather non intuitive. We can make the parametrisation more intuitive by reparametrising the beta in terms of mean and “standard deviation”
x<-seq(0.01,0.99, length=100)
plot(x,aqm::dmbeta(x,mean=0.5,sd=0.3), type="l", main="Beta distribution with mean of 0.5 and sd of 0.3")
If the sd is set to a high value the beta takes the form of a marmite type response.
plot(x,aqm::dmbeta(x,mean=0.5,sd=1), type="l", main="Beta distribution with mean of 0.5 and sd of 3")
The aqm package has a variation of rand_likert function which uses the beta distribution (bounded between 0 and 1) to represent the probability vector. This produces simulated responses with a known overall mean and “standard deviation”. Do note that the standard deviation is not that of a normal deviation. The beta distribution really has a shape and scale parameter and this is simply a convenient approximation to make using the function easier.
table(beta_likert(mean=0.1, sd=0.5)) ## Produces negative responses##
## Strongly disagree Disagree Neutral Agree
## 68 22 9 1
## Strongly agree
## 0Simulated ‘marmite’ response.
table(beta_likert(mean=0.5,sd=1)) ## Marmite responses##
## Strongly disagree Disagree Neutral Agree
## 18 17 21 22
## Strongly agree
## 22Simulating responses which follow a pattern linked to the characteristics of the subjects is rather more complex than simulating data that follows a normal distribution. We need to set up some underlying preference values around which there is some random noise. This is a latent beta distribution from which discrete answers are produced.
gender_effect<-rep(c(0.4,0.6),each=500) ## The female respondents tend to be more positive
age_effect<-age/100 ### Responses have a monotonic increase in positivity over the age range
## Simulate four questions
q1<-beta_likert_vec(age_effect,sd=0.6)
q2<-beta_likert_vec(age_effect,sd=0.6)
q3<-beta_likert_vec(gender_effect,sd=0.5)
q4<-beta_likert_vec(gender_effect,sd=0.5)
responses<-data.frame(id=1:1000,q1,q2,q3,q4)Ok. We now have simulated data in which the responses to questions 1 and 2 are strongly associated with a continuous age effect and questions 3 and 4 are associated with gender. In a real data set there would probably be additive and interactive effects. These can also be simulated, but we’ll keep it simple for the moment in order to clearly illustrate the analysis.
22.4.2 Joining the tables
The same approach can be taken to the data as previously. If the responses are first pivoted into a long data frame the subjects data can be joined as columns using the id as a common index.
df<-pivot_longer(responses, cols=-id,names_to="question",values_to = "response")
df<-inner_join(subjects,df)df %>% group_by(gender,question,response) %>% summarise(n=n()) %>% mutate(percent = round(100*n / sum(n),0)) -> tb22.4.3
ggplot(tb) +
aes(x = question, y = percent, fill = response, label=percent) +
geom_bar(stat="identity", width = 0.5)+
coord_flip() +
geom_text(aes(label = percent), position = position_stack(vjust = 0.5)) +
scale_fill_manual(
values = colorRampPalette(
RColorBrewer::brewer.pal(n = 5, name = "RdBu"))(6),
guide = guide_legend(reverse = TRUE)) + facet_wrap(~gender)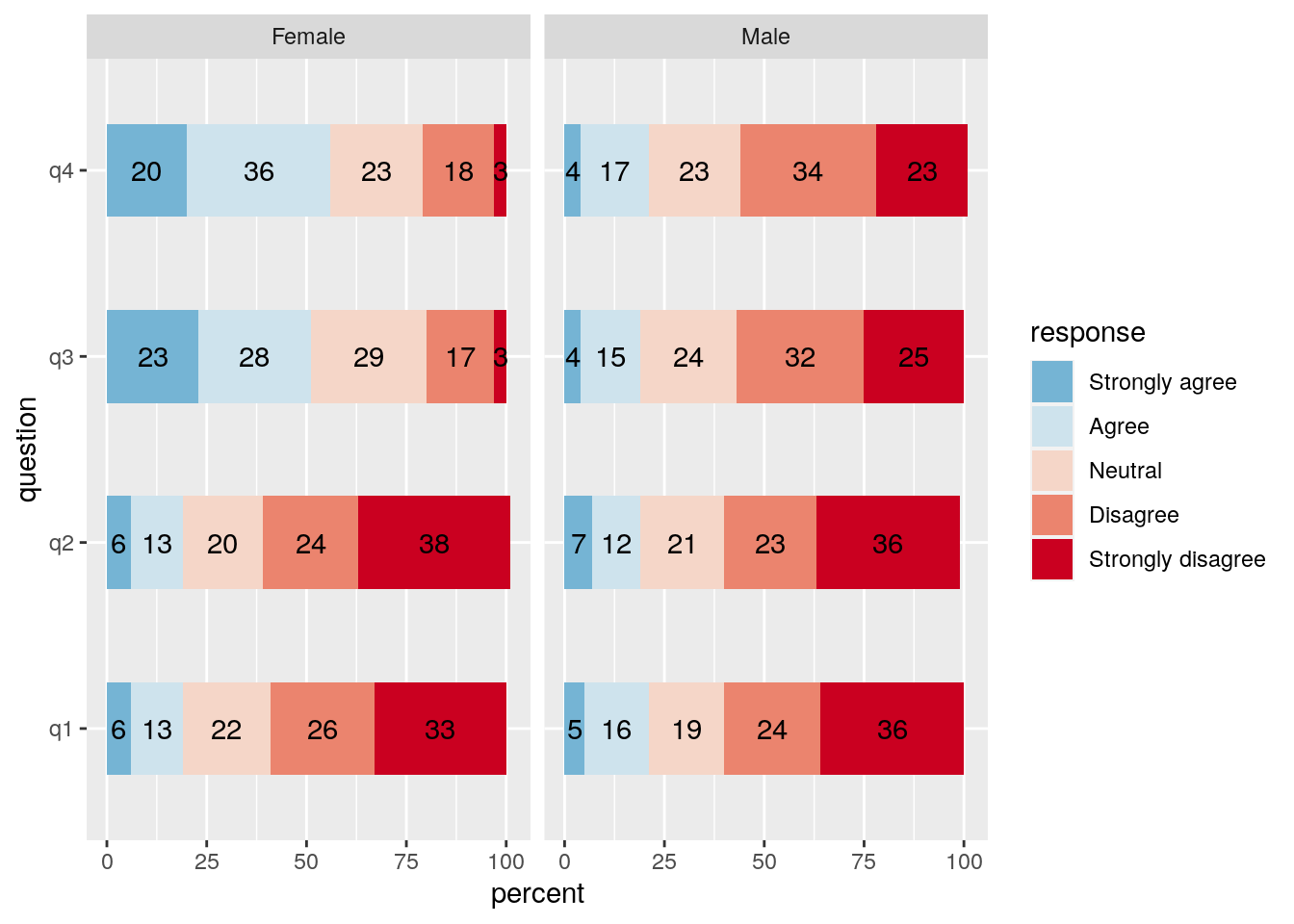
22.5 Statistical tests
Although many people do use simple statistical tests to look at associations between factors such as gender and responses on the Likert scale there are some issues when raw Likert data is used. As the scale is ordinal and bounded tests based on assumptions of normality of residuals are not valid. Lack of formal validity should not rule out using a statistical procedure entirely, as in real life all the assumptions of a statistical procedure are rarely met in full. Running a simple t-test is tolerable and should not be criticised too harshly. However it is not really the correct way to analyse the data.
df %>% filter(question =="q4") -> q4
t.test(as.numeric(q4$response)~ q4$gender)##
## Welch Two Sample t-test
##
## data: as.numeric(q4$response) by q4$gender
## t = 15.234, df = 997.61, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.9304271 1.2055729
## sample estimates:
## mean in group Female mean in group Male
## 3.510 2.442The Kruskall-Wallis test is also sometimes advised for Likert scale data. As it is based on ranks it is technically valid. There is no strong mathematical objection to using it. The null being tested is that the location parameters of the distribution of the scores are the same in each group. This is sometimes assumed to be a test that the median’s are not significantly different, but this is not quite the correct interpretation. This also shows no significant difference. However it is extremely hard to interpret and doesn’t lead to any clear measure of effect size. So not the correct procedure either.
kruskal.test(as.numeric(q4$response)~ q4$gender)##
## Kruskal-Wallis rank sum test
##
## data: as.numeric(q4$response) by q4$gender
## Kruskal-Wallis chi-squared = 187.47, df = 1, p-value < 2.2e-1622.5.1 Analysing as a binary responses
One common way to deal with Likert scale data that at least partially adresses the potential “marmite” issue is to simplify the data into binary classes and look at the number of responses falling into each class. This is the approach which is taken when analysing NSS scores in order to form University league tables. The measure typically used is the proportion of students who are satisfied i.e. giving a score above 3 on the Likert scale.
We can use ones and zeros to represent satisfaction.
df %>% mutate(satisfied=1*(as.numeric(response)>3)) ->dfOnce we have converted the scale into zeros and ones then the total satisfaction for a question is simply the sum of these ones and zeros.
The binom.test function in R produces 95% confidence intervals on the proportion of successes as one of its outputs. So we can use that to produce a table holding the proportion satisfied, converted to a percentage together with the appropriate upper and lower 95% confidence intervals.
binom_ci<-function(p,n){
b<-binom.test(p,n)
round(b$conf.int*100,1)
}
df %>% group_by(gender,question) %>% summarise(n=n(),satisfied=sum(satisfied), lwr=binom_ci(satisfied,n)[1],percent=round(100*satisfied/n,1),upr=binom_ci(satisfied,n)[2]) -> bin_table
dt(bin_table)The results can now be turned into a figure which is conditioned on gender using a facet wrap.
g0<-ggplot(bin_table,aes(x=gender)) + geom_point(aes(y=percent),colour="red") + facet_wrap(~question, scales="free")
g1<-g0+geom_errorbar(aes(ymin=lwr,ymax=upr))
g1
The figure allows us to quickly screen the questions for significant results. When the confidence intervals do not overlap then a statistical test using logistic regression (generalised linear model of the binomial family) will produce a p-value below 0.05.
df %>% filter(question=='q3') -> q3
mod<-glm(data=q3,satisfied~gender,family='binomial')
summary(mod)##
## Call:
## glm(formula = satisfied ~ gender, family = "binomial", data = q3)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.1876 -0.6605 -0.6605 1.1672 1.8054
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.02400 0.08945 0.268 0.788
## genderMale -1.43549 0.14385 -9.979 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1296.1 on 999 degrees of freedom
## Residual deviance: 1187.9 on 998 degrees of freedom
## AIC: 1191.9
##
## Number of Fisher Scoring iterations: 422.5.2 Visualising response to a continuous variable
Logistic regression can also be used to analyse the response to a continuous variable. In order to visualise the response we can add a smoother to a ggplot using glm as the model fitting method. This produces lines with confidence intervals.
g1<-ggplot(df,aes(x=age,y=satisfied))
g1<-g1+stat_smooth(method="glm",method.args=list(family="binomial"),formula=y~x) +facet_wrap(~question)
g1
If we suspected that the response may in fact be more complex we could experiment by fitting gams instead of glms.
library(mgcv)
g1<-ggplot(df,aes(x=age,y=satisfied))
g1<-g1+stat_smooth(method="gam",method.args=list(family="binomial"),formula=y~s(x,k=3)) +facet_wrap(~question)
g1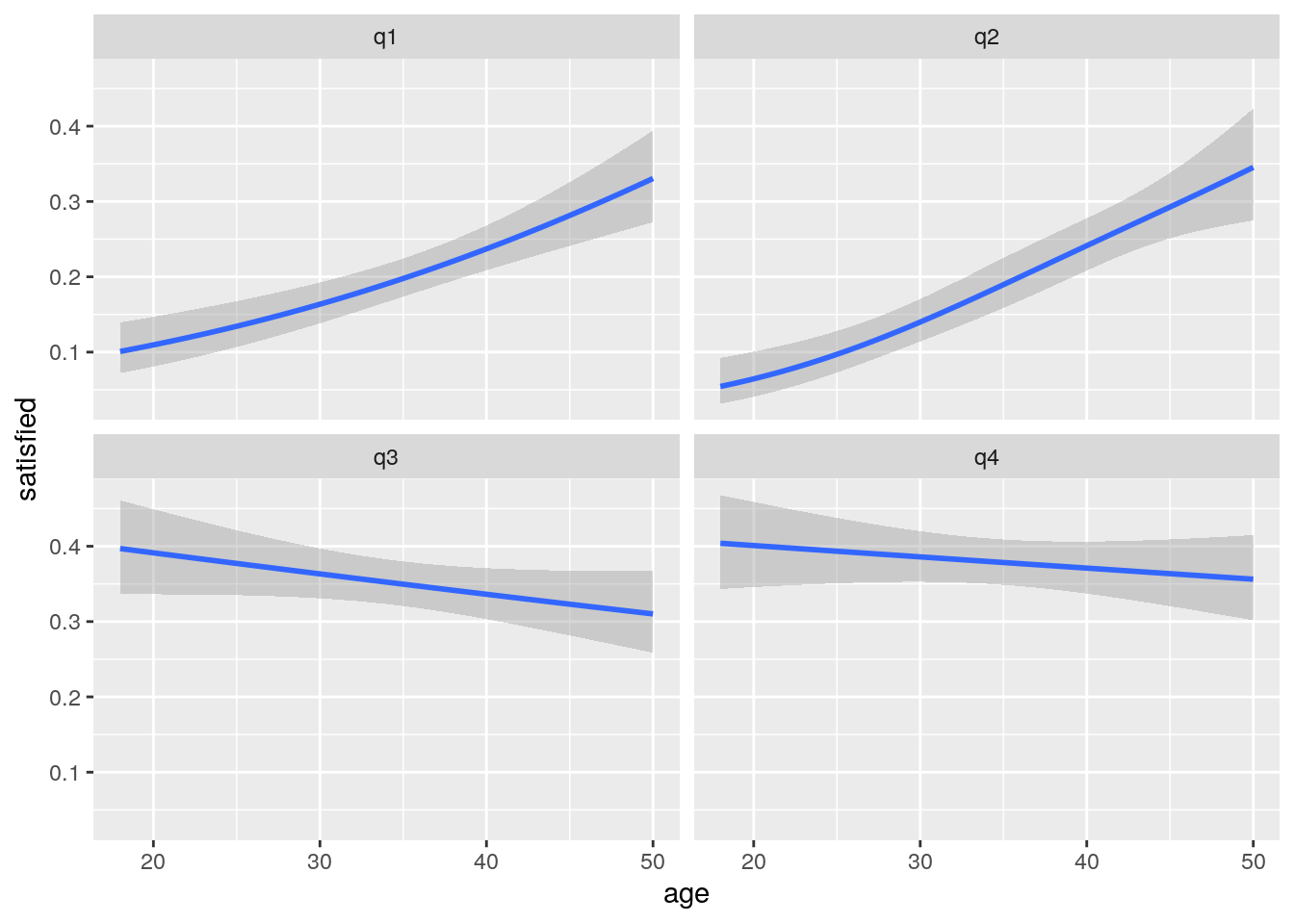
The results in this case are very similar, as we would expect.
Statistical tests can be run for each question by fitting a logistic regression.
df %>% filter(question=='q1') -> q1
mod<-glm(data=q1,satisfied~age,family='binomial')
summary(mod)##
## Call:
## glm(formula = satisfied ~ age, family = "binomial", data = q1)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.8959 -0.7357 -0.5978 -0.4715 2.1417
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.020406 0.338962 -8.911 < 2e-16 ***
## age 0.046294 0.008909 5.196 2.04e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1011.80 on 999 degrees of freedom
## Residual deviance: 983.28 on 998 degrees of freedom
## AIC: 987.28
##
## Number of Fisher Scoring iterations: 4So the analysis has correctly discovered the bivariate relationships that were used to simulate the data. The analysis can then be extended to analyse the response with respect to both explanatory variables together.
df %>% filter(question=='q1') -> q1
mod<-glm(data=q1,satisfied~age + gender,family='binomial')
summary(mod)##
## Call:
## glm(formula = satisfied ~ age + gender, family = "binomial",
## data = q1)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.9182 -0.7295 -0.5929 -0.4678 2.1678
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.080106 0.348058 -8.849 < 2e-16 ***
## age 0.046148 0.008918 5.174 2.29e-07 ***
## genderMale 0.126883 0.159437 0.796 0.426
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1011.80 on 999 degrees of freedom
## Residual deviance: 982.65 on 997 degrees of freedom
## AIC: 988.65
##
## Number of Fisher Scoring iterations: 422.5.3 Screening all questions
f<-function(y,x1,x2)summary(glm(y~x1+x2,family='binomial'))$ coefficients[,4]
df %>% group_by(question) %>% summarise(p_val_age=round(f(satisfied,age,gender)[2],3), p_val_gender=round(f(satisfied,age,gender)[3],3)) %>% dt()22.5.4 Latent factor analysis
Factor analysis is a potentially very useful method for analysing questionnaire data from a psychometric perspective. The purpose of factor analysis is to estimate a model that explains the observed covariance structure in the data collected in terms of a set of unobserved factors and weightings. The aim of factor analysis is parsimony of description. In other words we want to look at the relationships between many observed variables in terms of a more limited set of components or latent factors.
There is a clear explanation of the mathematics involved here
https://www.youtube.com/watch?v=WV_jcaDBZ2I&list=PLwJRxp3blEvaOTZfSKXysxRmi6gXJf5gP&index=2&t=0s
The best package for running factor analysis on
http://www.personality-project.org/r/book/
The site contains a lot of material on psychometrics including an interesting personality test.
Let’s make up some data to illustrate the idea behind latent factor analysis in a straightforward, hopefully easily understood way. Imagine we have set up a questionnaire that aims to look at people’s personalities in terms of just two main traits. Perhaps we are interested in musicians and other stage performers. Musicians are creative people, but despite being in public view they are not all necessarily extroverted. The two traits might be completely unrelated.
The logic behind latent factor analysis is that we have an idea about the possible existence of some underlying factors, but until we have obtained data from the questionnaire we don’t really know the extent to which each question is really associated (correlated) with these underlying factors. When we are making up simulated data we do already know the answer of course.
Let’s assume we are going to survey 300 people with a range of hidden scores on two axes. The axes in our simulated data are completely orthogonal, in other words we are assuming that there is no correlation between extroversion and creativity. In practice this may not be true and a detailed analysis can actually tease apart some subtle patterns of correlations between latent factors. However the more complex the relationships the more data that will be required set. Tens of thousands of observations may be needed to look at complex hierarchical structures involving five or more latent factors. For two latent factors which are truly orthogonal our survey may be sufficiently large, providing that the actual questions have been skilfully designed and well targeted towards a statistical analysis of the hypotheses we have in mind.
id<-1:300
extroversion<-rmbeta(300,0.5,0.5)
creativity<-rmbeta(300,0.5,0.5)
plot(extroversion,creativity)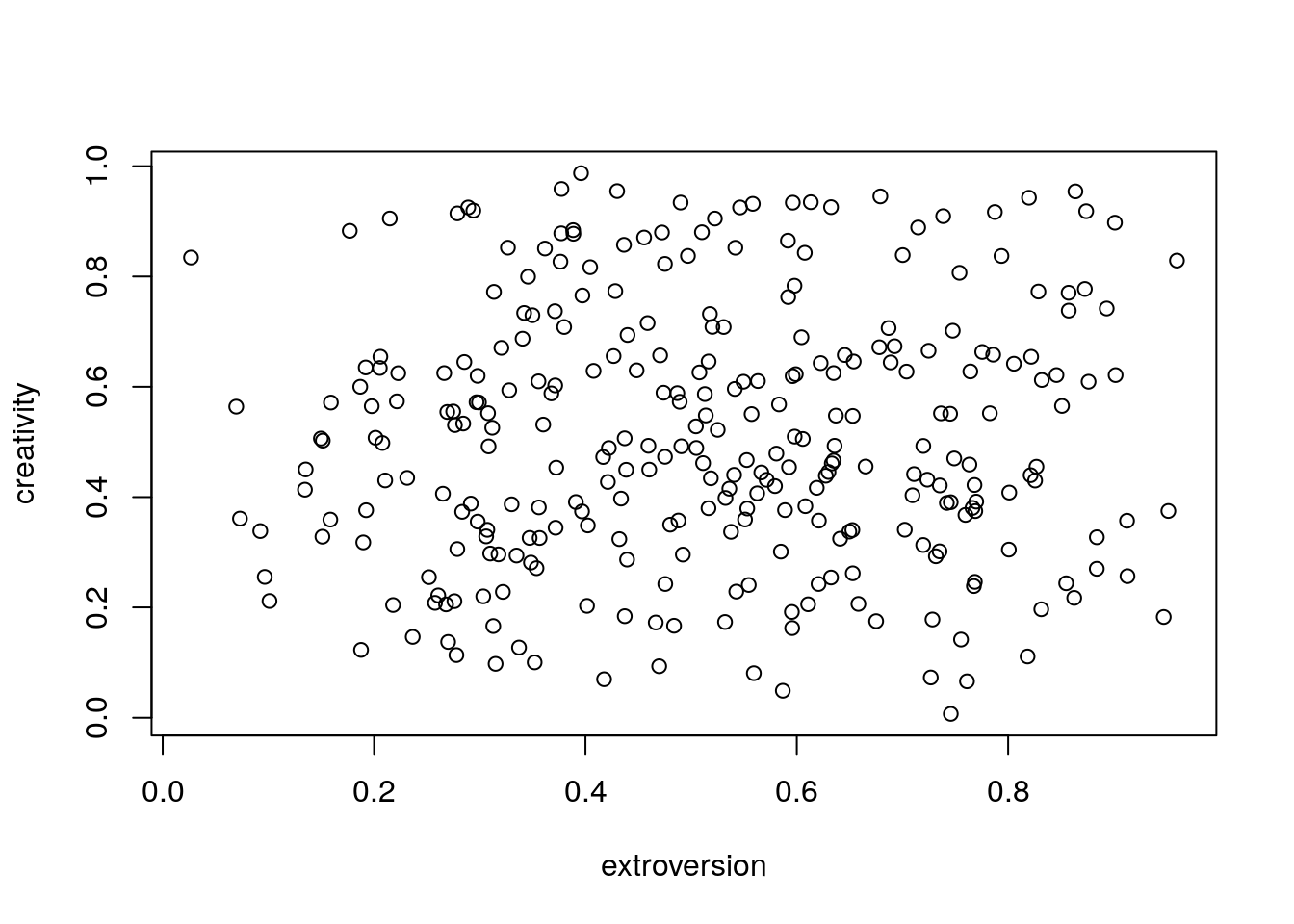
Notice that for illustrative purposes there is no effect of additional covariates such as gender, age etc. In a real study we certainly would be interested in the covariates. In fact one on of the key strengths of factor analysis is that like PCA (which it is based on) it is form of data reduction. The scores on the reduced axes can then be related to other factors. So we might in fact be interested in finding out if extroversion is related to gender. If we were simulating data with differences we would set them up at this stage.
22.5.5 Setting up the data frame
We can use the beta_likert_vec function in aqm to set up Likert responses which are correlated with the hidden factors.
q1<-beta_likert_vec(extroversion)
q2<-beta_likert_vec(extroversion)
q3<-beta_likert_vec(extroversion)
q4<-beta_likert_vec(extroversion)
q5<-beta_likert_vec(extroversion)
q6<-beta_likert_vec(creativity)
q7<-beta_likert_vec(creativity)
q8<-beta_likert_vec(creativity)
q9<-beta_likert_vec((creativity+extroversion)/2)
q10<-beta_likert_vec((creativity+extroversion)/2)
d<-data.frame(q1,q2,q3,q4,q5,q6,q7,q8,q9,q10)22.5.6 Data manipulation
The function simulates data as an ordered factor. To change the responses into numbers on a scale of 1 to 5 use coercion. Note that the dplyr mutate_all is very handy for this, but it is only appropriate if all the columns hold the same type of data (i.e. it might go wrong if an id column was included)
d_num<-mutate_all(d,as.numeric)Another approach is to convert the Likert scale responses to binary scores.
f<-function(x)1*(x>3)
d_bin<-mutate_all(d_num,f)22.5.7 Correlation matrix
In order to look at relationships between the numerical values we could use rank correlation. Using Pearson’s would not be correct. However this is really only an exploratory analysis and in many situations it would produce similar results.
rank_cor <- cor(d_num,method="spearman")
cor.plot(rank_cor, numbers=T, upper=FALSE, main = "Rank Correlation", show.legend = FALSE)
When running factor analysis on Likert scale data we will usually use either polychoric or tetrachoric correlation. Polychoric correlation estimates the correlation between two theorised normally distributed continuous latent variables, from two observed ordinal variables. Tetrachoric correlation uses just about the same underlying mathematics but is the name given to polychoric correlation both observed variables are dichotomous. If you already know some stats you can think of polychoric correlation as being rather like runing a chisq test on a contingency table made up by crossing observations. For example crossing question1 and question 2 produces the following table
table(d$q1,d$q2)##
## Strongly disagree Disagree Neutral Agree Strongly agree
## Strongly disagree 26 8 12 10 1
## Disagree 12 16 20 6 2
## Neutral 10 11 8 15 12
## Agree 2 8 21 12 15
## Strongly agree 3 6 10 25 29A mathematical issue can arise if some of the cells are empty. R will warn you of this and make a correction when the procedure is applied.
22.5.8 Polychoric scree plots
There are many different procedures for selecting the number of factors to extract from the data. The most commonly used approach is the scree plot. This is named after the screes on mountain sides. The idea is that the random variability forms a pile of scree at the foot of the slope. A steep slope implies a small number of factors.
fa.parallel(d_num, fm="minres", fa="fa", cor='poly', main = "Polychoric scree plot based on ordinal responses")## Warning in matpLower(x, nvar, gminx, gmaxx, gminy, gmaxy): 4 cells were adjusted
## for 0 values using the correction for continuity. Examine your data carefully.
## Parallel analysis suggests that the number of factors = 2 and the number of components = NAfa.parallel(d_bin, fm="minres", fa="fa", cor='tet', main = "Tetrachoric scree plot based on binary responses")
## Parallel analysis suggests that the number of factors = 3 and the number of components = NAmod1<-fa(d_num, nfactor=2, cor="poly", fm="mle", rotate = "oblimin")## Warning in matpLower(x, nvar, gminx, gmaxx, gminy, gmaxy): 4 cells were adjusted
## for 0 values using the correction for continuity. Examine your data carefully.mod2<-fa(d_bin, nfactor=2, cor="tet", fm="mle", rotate = "oblimin")mod1$loadings##
## Loadings:
## ML1 ML2
## q1 0.738
## q2 0.731
## q3 0.796
## q4 0.664
## q5 0.654
## q6 0.734
## q7 0.747
## q8 0.800
## q9 0.460 0.426
## q10 0.431 0.474
##
## ML1 ML2
## SS loadings 2.989 2.154
## Proportion Var 0.299 0.215
## Cumulative Var 0.299 0.514fa.diagram(mod1,simple=FALSE)
fa.diagram(mod2,simple=FALSE)
hist(mod1$scores[,1])
22.5.9 Hierarchical factors and item response theory
Analysis of real life data can be a much more complex task. Some data sets may appear to have only one latent factor when in reality this is a compound of elements that can be broken down further. An example of this sort of hierachical data is included in the psych package. The ability data set is based on tests of ability on four lower order factors (verbal reasoning, letter series, matrix reasoning, and spatial rotations). These are all highly correlated with overall analytical ability. So a scree plot seems to suggest that there is only one factor.
data(ability)
fa.parallel(ability, fm="minres", fa="fa", cor='tet', main = "Tetrachoric scree plot based on binary responses")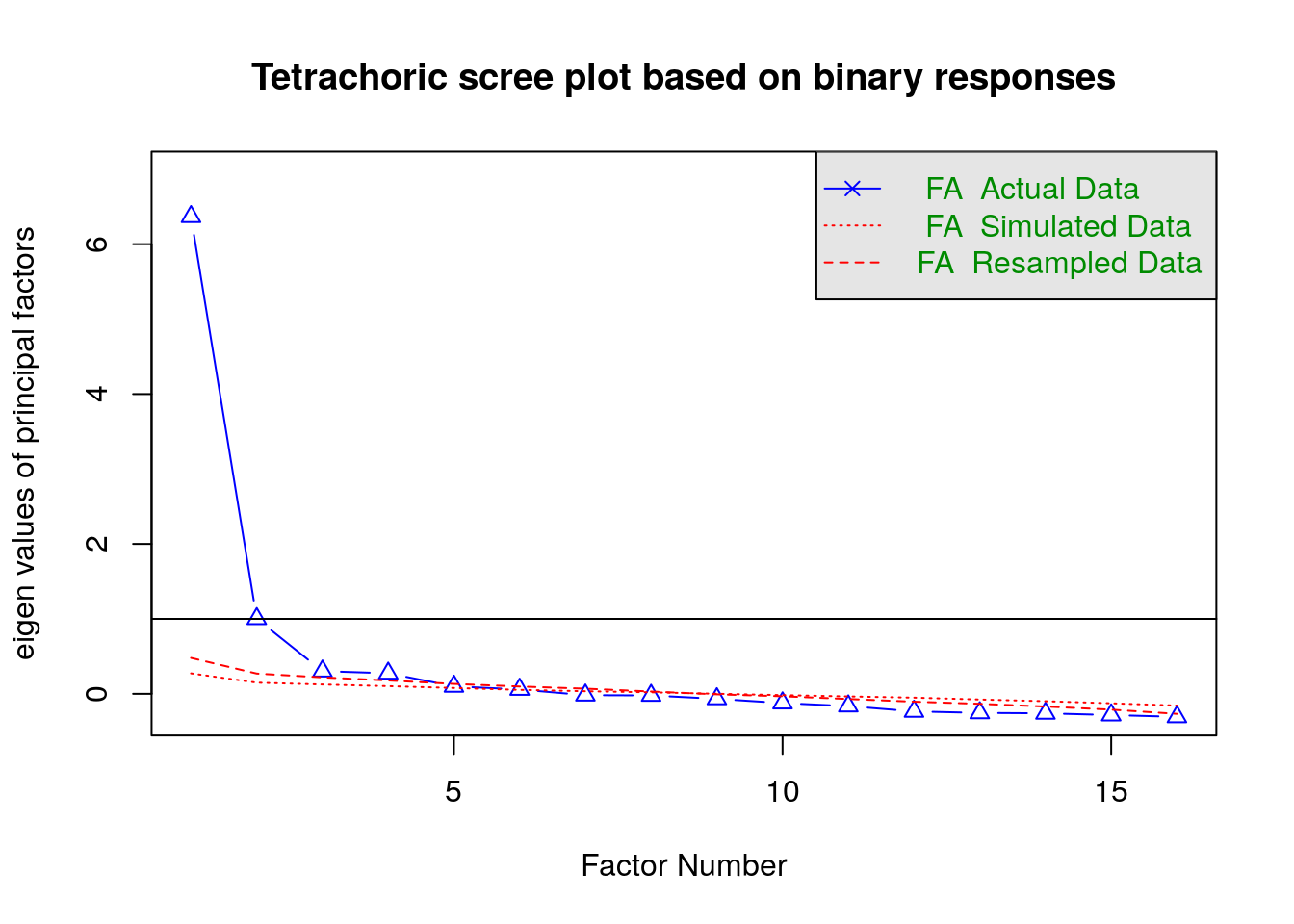
## Parallel analysis suggests that the number of factors = 6 and the number of components = NAmod_ability<-fa(d_bin, nfactor=4, cor="tet", fm="mle", rotate = "oblimin")fa.diagram(mod_ability,simple=FALSE)