Chapter 18 Generalised linear models
So far we have assumed throughout that the variability in our models takes an approximately normal form. This is the assumption used in the classical parametric statistical tests and in regression, ANOVA and ANCOVA. Violations of the assumption often lead to the adoption of simple non parametric tests instead of more informative model based procedures due to worries about not meeting the assumptions needed for parametric modelling. However the set of models, known as Generalised Linear Models (GLMs) can use any known distribution for the errors. These are very powerful techniques. They are not much more difficult to apply using R than the methods that you have already seen. However careful thought is required in order to find the correct form for the model.
18.1 Poisson regression
Let’s look at the marine invertebrates data that we saw earlier.
d<-read.csv("https://tinyurl.com/aqm-data/marineinverts.csv")
str(d)## 'data.frame': 45 obs. of 4 variables:
## $ richness: int 0 2 8 13 17 10 10 9 19 8 ...
## $ grain : num 450 370 192 194 197 ...
## $ height : num 2.255 0.865 1.19 -1.336 -1.334 ...
## $ salinity: num 27.1 27.1 29.6 29.4 29.6 29.4 29.4 29.6 29.6 29.6 ...Plotting species richness against grain size again.
attach(d)
plot(d$richness~d$grain)
In the previous analysis we looked at how allowing the model to adopt a curved form led to a better fit. However the issue of the inappropriate use of the normal distribution to represent the error term was ignored.
One way of thinking about the situation is to remember that the description of a regression line includes some statement about the errors.
\(y=a+bx+\epsilon\) where \(\epsilon=N(o,\sigma^{2})\)
This equation should be able to describe the process that leads to each data point. The model has a deterministic component (the regression line) and a stochastic component (the error term). However when the points are counts a continuous error term is incorrect. Although the mean value (trend) does not have to be an integer value, the actual data values do. So the errors around the trend should be discrete.
The poisson distribution can represent this. For any value of lambda (which is continuous) the probability distribution of values is discrete. The poisson distribution automatically builds in heterogeniety of variance as the variance of a poisson distribution is in fact equal to lambda.
par(mfcol=c(2,2))
barplot(dpois(0:5,lambda=0.1),names=0:5,main="Lambda=0.1")
barplot(dpois(0:5,lambda=0.5),names=0:5,main="Lambda=0.5")
barplot(dpois(0:5,lambda=1),names=0:5,main="Lambda=1")
barplot(dpois(0:5,lambda=2),names=0:5,main="Lambda=2")
Let’s think of a regression line with poisson errors with a=0, and b=1.
\(y=a+bx+\epsilon\) where \(\epsilon=poisson(lambda=y)\)
Something interesting happens in this case. Lambda is a measure of the central tendency, but for most of the regression line no observations can actually take the value of lambda. A point can only fall on the line when lambda happens to be an integer.
lambda<-seq(0,10,length=200)
plot(lambda,rpois(200,lambda),pch=21,bg=2)
lines(lambda,lambda,lwd=2)
abline(v=0:10,lty=2)
This is the motive for fitting using maximum likelihood. A point that falls a long way away from the deterministic component of a model contributes more to the model’s deviance than one that is close. A model with a low total deviance has a higher likelihood than one with a high deviance. The probabilities (that contribute to the deviance) are determined from assumptions regarding the form of the stochastic component of the model. The normal distribution is only one form of determining these probabilities. There are many other possible distributions for the error term.
So let’s fit the model again, this time using poisson regression. By default this uses a log link function. This is usually appropriate for count data that cannot fall below zero. In this case the logarithmic link function also deals nicely with the problem of curvilinearity of the response.
mod1<-glm(data=d,richness ~ grain,family=poisson)
summary(mod1)##
## Call:
## glm(formula = richness ~ grain, family = poisson, data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.4828 -1.3897 -0.0732 0.8644 2.5838
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.238393 0.299033 14.174 < 2e-16 ***
## grain -0.009496 0.001179 -8.052 8.16e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 179.75 on 44 degrees of freedom
## Residual deviance: 105.35 on 43 degrees of freedom
## AIC: 251.35
##
## Number of Fisher Scoring iterations: 5confint(mod1)## 2.5 % 97.5 %
## (Intercept) 3.65451714 4.827458978
## grain -0.01185141 -0.007224939Plotting the model shows it’s form. Note that with when fitting a GLM in R we can ask for the standard errors and produce approximate confidence intervals using them.
plot(d$richness ~ d$grain)
x<-seq(min(d$grain),max(d$grain),length=100)
a<-predict(mod1,newdata=list(grain=x),type="response",se=T)
lines(x,a$fit-2*a$se.fit,lty=2)
lines(x,a$fit+2*a$se.fit,lty=2)
lines(x,a$fit)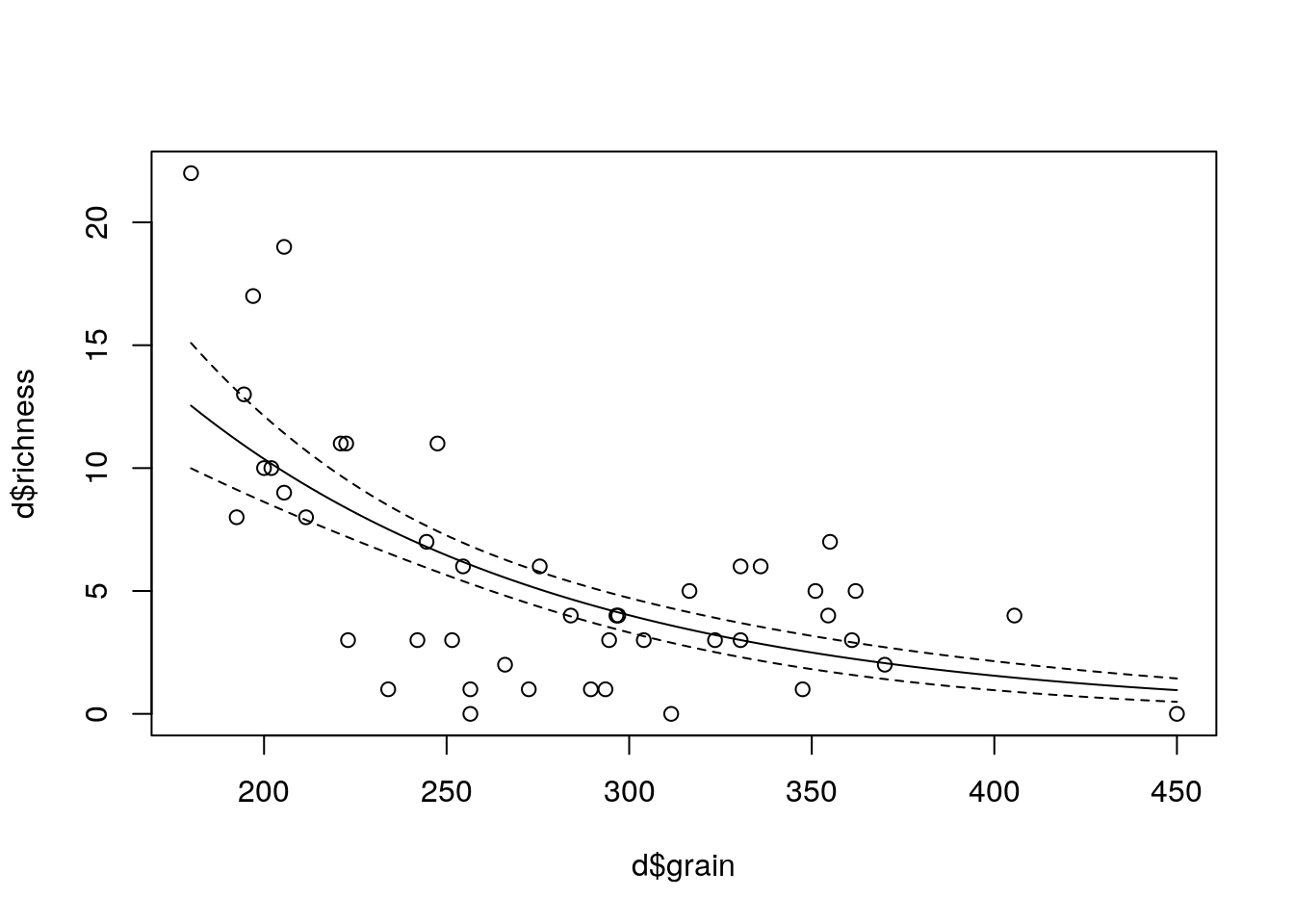
18.2 GGplot
Its easy to add a glm to a ggplot scatterplot. However be careful to add in the methods.args.
library(ggplot2)
g0<-ggplot(d,aes(x=grain,y=richness))
glm1<-g0+geom_point()+stat_smooth(method="glm",method.args=list( family="poisson"), se=TRUE) +ggtitle("Poisson regression with log link function")
glm1
18.3 Showing the results with logged y
This is not a good approach, as the zeros are lost, but it demonstrates the idea.
plot(d$richness ~d$grain, log="y")
x<-seq(min(grain),max(grain),length=100)
a<-predict(mod1,newdata=list(grain=x),type="response",se=T)
lines(x,a$fit-2*a$se.fit,lty=2)
lines(x,a$fit+2*a$se.fit,lty=2)
lines(x,a$fit)
18.4 Log link function explained
The coefficients of the model when we ask for a summary are rather hard to undertand.
summary(mod1)##
## Call:
## glm(formula = richness ~ grain, family = poisson, data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.4828 -1.3897 -0.0732 0.8644 2.5838
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.238393 0.299033 14.174 < 2e-16 ***
## grain -0.009496 0.001179 -8.052 8.16e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 179.75 on 44 degrees of freedom
## Residual deviance: 105.35 on 43 degrees of freedom
## AIC: 251.35
##
## Number of Fisher Scoring iterations: 5The slope is given as -0.009. What does this mean? Unlike a regeression slope it is NOT the change in y for a unit change in x, as we are using a logarithmic link function.
In generalized linear models, there is always some sort of link function, which is the link between the mean of Y on the left and the predictor variable on the right. It is possible to use the identity link, which leaves the result the same, but typically some other link function is used. The identity link is not a good choice for data with many zeros.
Formally the link function is ..
\(f(y|x ) = a + bx\)
I.e. Some function of the conditional value of y on x, ignoring the residual error, is predicted by a regression equation rather than simply y.
The log link function exponentiates the linear predictors. It does not actually involve a log transform of the outcome variable.
\(y = exp(a + bx)\)
Which could be also written as ..
\(y = e^{a +bx}\)
As the logarithm used is the natural logarithm this implies that expected value of y is multiplied by \(exp(b)\) as we increase the value of x by 1 unit.
This is not intuitive.
Exponentiating the coefficients in R for the model above produces this result..
exp(coef(mod1))## (Intercept) grain
## 69.2963902 0.9905485So, the intercept,for a grain size of zero is 69.3 and for each unit increase in grain size the diversity is changed by 99.055 % of the previous value. This is a process of exponential decay, as the richness is falling away steadily with each unti increase in grain size, but the model never leads to a predicted species richness below zero.
One way to make all this a little more understandable is to divide the natural logarithm of 2 (0.69) by the raw slope coefficient, which was found to be -0.009.
log(2)/(coef(mod1)[2])## grain
## -72.99001This is using the formula for the half life, or doubling time, in an expenential decay or growth model.
So, in order to double the expected species richness we therefore would have to change the grain size by -72.99 units.
When presenting the results to a mathematically sophisticated audience you can safely place the coefficients within the equation and expect the audience to make sense of it.
\(y = e^{a +bx}\)
When explaining the result in words you can say that a change in grain size of -72.99 leads to doubling of expected species richness.
Showing a scatterplot with the fitted line is usually the easiest way to visualise the model and to make sense of it intuitively.
18.4.1 Likelihood and deviance
In order to fully understand all the elements used when analysing a GLM we also need at least an intuitive understanding of the concepts of likelihood and deviance.
Models are fit by maximising the likelihood. But, what is the likelihood?
To try to inderstand this, let’s first obtain some simple count data. We can simulate the counts from a poisson distribution.
set.seed(10)
x<-rpois(10,lambda=2)
x## [1] 2 1 2 3 0 1 1 1 2 2barplot(table(x))
We can fit a simple model that just involves the intercept (mean) using R. This is.
mod<-glm(x~1,poisson(link="identity"))
summary(mod)##
## Call:
## glm(formula = x ~ 1, family = poisson(link = "identity"))
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.73205 -0.43482 -0.02329 0.38824 1.07651
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.5000 0.3873 3.873 0.000108 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 5.5181 on 9 degrees of freedom
## Residual deviance: 5.5181 on 9 degrees of freedom
## AIC: 28.965
##
## Number of Fisher Scoring iterations: 3coef(mod)## (Intercept)
## 1.5confint(mod)## 2.5 % 97.5 %
## 0.8635729 2.3923065lam<-coef(mod)Now, under the poisson model we can calculate a probability of getting any integer from a poisson distribution with a mean of lambda using a standard formula that is built into R. So the probability of getting a zero is dpois(0,lambda=2.1)
dpois(0,lambda=2.1)=0.223
dpois(1,lambda=2.1)=0.335
dpois(2,lambda=2.1)= 0.251
dpois(3,lambda=2.1)=0.126
dpois(4,lambda=2.1)=0.047
What this means is that we have a probability (likelihood) for each of the data points given the model parameter (lambda). We can look at this as a barplot of counts of each probability value.
dx<-dpois(x,lambda=lam)
dx## [1] 0.2510214 0.3346952 0.2510214 0.1255107 0.2231302 0.3346952 0.3346952
## [8] 0.3346952 0.2510214 0.2510214barplot(table(round(dx,3)))
The probability of getting EXACTLY the data that we have is the product of all these probabilities, as we find the combined probability of independent events by multiplying them together. Because this is going to result in very small numbers it is usually easier to work with logarithmns and add them together. Hence the term log likelihood that you will see used in all treatments of GLMs.
loglik<-sum(log(dx))
loglik## [1] -13.48237logLik(mod)## 'log Lik.' -13.48237 (df=1)OK, so that was not too difficult. Notice as well that this calculation gave us the maximum likelihood. If we had used any other value as an estimate for lambda we would have got a lower value expressed as a negative value.
sum(log(dpois(x,lambda=1)))## [1] -14.56435sum(log(dpois(x,lambda=lam)))## [1] -13.48237sum(log(dpois(x,lambda=3)))## [1] -18.08516In order to simplify matters further we remove the sign and work with -2 log likelihood.
-2*sum(log(dpois(x,lambda=lam)))## [1] 26.96474The AIC which we will look at later in the course as a way of comparing two models combines the -2 log likelihood with the number of parameters (k). In this case we have just one parameter so AIC adds 2 to the number we previously calculated.
AIC=2k-2ln(L)
AIC(mod)## [1] 28.96474Now finally, what does the deviance refer to?
Well, even a model which has a separate parameter for each data point will still have a likelihood below one. The deviance refers to the difference in -2 log likelihood between the fully saturated model and the actual model. We can get the -2 log likelihood for this model as well.
dpois(x,lambda=x)## [1] 0.2706706 0.3678794 0.2706706 0.2240418 1.0000000 0.3678794 0.3678794
## [8] 0.3678794 0.2706706 0.2706706satmod<--2*sum(log(dpois(x,lambda=x)))
satmod## [1] 21.44667Just to confirm, this should give us the deviance.
-2*loglik-satmod## [1] 5.518075deviance(mod)## [1] 5.518075Notice that we had ten data points (residual degrees of freedom = n-1 = 9) and a residual deviance that is around 10. This is an indication that the assumption of Poisson distributed residuals is a reasonable one as for mathematical reasons that we need not go into we would expect an addition of just under 1 to the deviance for each additional data point.
Going back to the summary of the model
summary(mod)##
## Call:
## glm(formula = x ~ 1, family = poisson(link = "identity"))
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.73205 -0.43482 -0.02329 0.38824 1.07651
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.5000 0.3873 3.873 0.000108 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 5.5181 on 9 degrees of freedom
## Residual deviance: 5.5181 on 9 degrees of freedom
## AIC: 28.965
##
## Number of Fisher Scoring iterations: 3We can see that in this artificial case the null deviance and the residual deviance are identical. This is because the null is “true”. There is nothing to report in the model apart from the intercept, i.e. a single value for lambda. If we use this concept in a model with a predictor variable we should see a difference between these two numbers. The larger the diffence, the more of the deviance is “explained” by our predictor. We want to reduce the deviance bt fitting a model, so if there is a relationship the residual deviance should always be lower than the null deviance.
18.4.1.1 Overdispersion
If the residual deviance is larger than residual degrees of freedom we have overdispersion (extra, unexplained variation in the response).
summary(mod1)##
## Call:
## glm(formula = richness ~ grain, family = poisson, data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.4828 -1.3897 -0.0732 0.8644 2.5838
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.238393 0.299033 14.174 < 2e-16 ***
## grain -0.009496 0.001179 -8.052 8.16e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 179.75 on 44 degrees of freedom
## Residual deviance: 105.35 on 43 degrees of freedom
## AIC: 251.35
##
## Number of Fisher Scoring iterations: 5This means that in fact the measured variance in the data, after taking into account the regression line, is still larger than the lambda values over the range of the regression. This is extra variability that goes beyond that expected under the assumption that the residuals are poisson distributed.
This is the diagnostic tool which is used in Poisson regression. The point is that under a poisson distribution the variance is fixed. It is always identical to the mean (lamda). This may not be a reasonable assumption, but it is the assumption being made. If it is not met we will need to make some compensation for this in order to produce a more justifiable model.
18.4.1.2 Quasi-poisson regression
A simple way of dealing with over dispersion is to use so called quasi-poisson regression. This finds a weight so that instead of assuming that the variance is equal to lambda the assumption is made that it is equal to some multiple of lambda. The multiple is estimated from the data. The effect is to reduce the significance of the regression term and widen the confidence intervals. It is a rather outdated technique that has some problems, but we’ll try it anyway.
mod2<-glm(data=d,richness ~ grain,family=quasipoisson)
summary(mod2)##
## Call:
## glm(formula = richness ~ grain, family = quasipoisson, data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -3.4828 -1.3897 -0.0732 0.8644 2.5838
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.238393 0.441806 9.593 3.00e-12 ***
## grain -0.009496 0.001743 -5.450 2.29e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for quasipoisson family taken to be 2.182862)
##
## Null deviance: 179.75 on 44 degrees of freedom
## Residual deviance: 105.35 on 43 degrees of freedom
## AIC: NA
##
## Number of Fisher Scoring iterations: 5AIC(mod2)## [1] NAconfint(mod2)## 2.5 % 97.5 %
## (Intercept) 3.376924 5.11119746
## grain -0.013008 -0.00616704Notice that the confidence intervals are wider. However we cannot obtain a value for AIC from a quasi model as the likelihood function is not fully defined. This limits the application of quasi poisson models, so we’ll pass on quickly to a rather more useful approach..
glm2<-g0+geom_point()+geom_smooth(method="glm", method.args=list(family="quasipoisson"), se=TRUE) + ggtitle("Quasipoisson regression")
glm2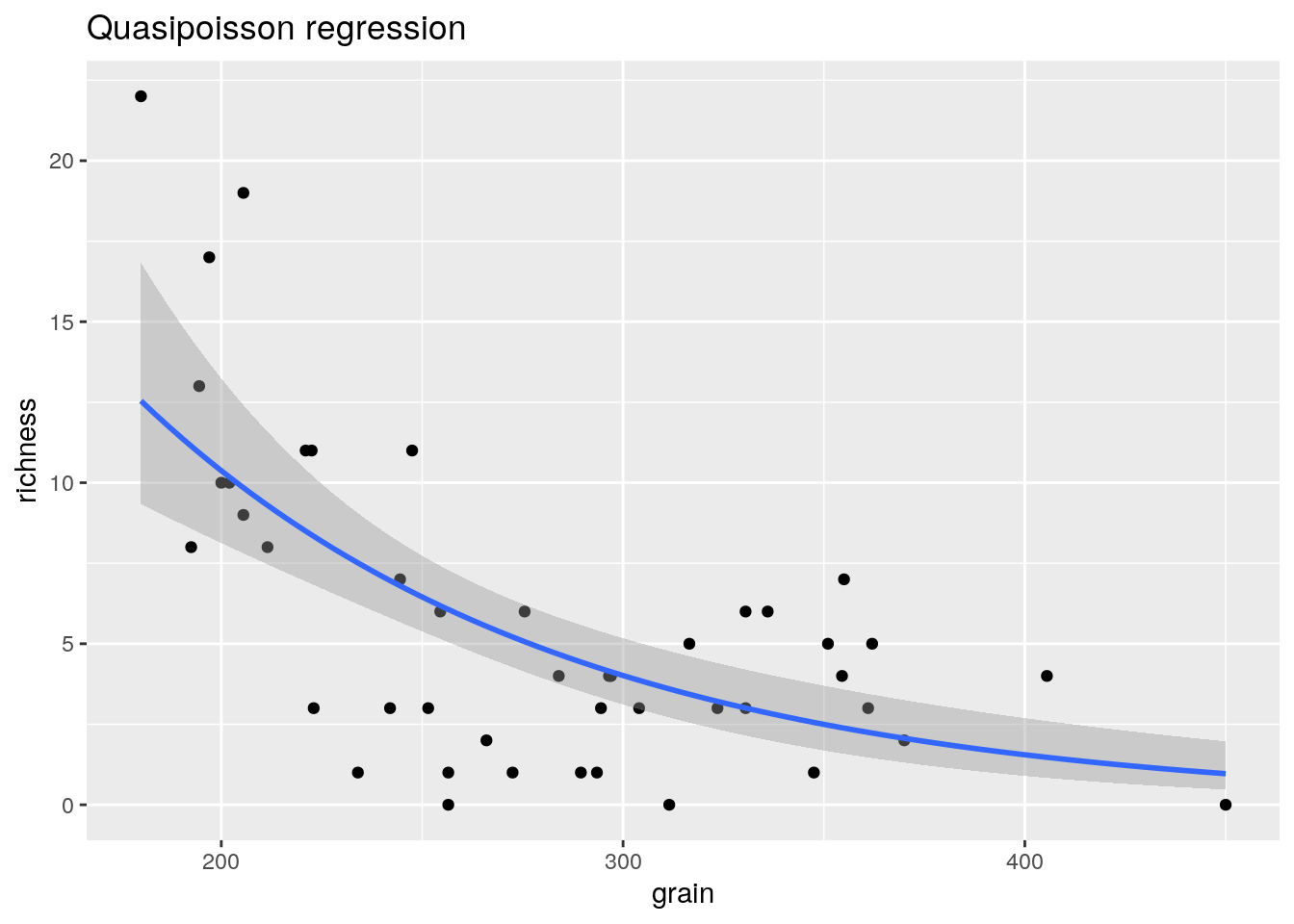
18.4.2 Negative binomial regression
As we have seen, there is a problem with quasi poisson regression.There is no defined form for the likelihood. Therefore it is impossible to calculate AIC. This makes it difficult to run model comparisons using quasi poisson models. An alternative is to fit the model assuming a negative binomial distribution for the error terms. This is a well defined model for over dispersed count data.
library(MASS)
mod3<-glm.nb(data=d,richness ~ grain)
summary(mod3)##
## Call:
## glm.nb(formula = richness ~ grain, data = d, init.theta = 4.008462461,
## link = log)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.7113 -1.0326 -0.1109 0.5508 1.5622
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.886804 0.467175 8.320 < 2e-16 ***
## grain -0.008155 0.001713 -4.762 1.92e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for Negative Binomial(4.0085) family taken to be 1)
##
## Null deviance: 79.302 on 44 degrees of freedom
## Residual deviance: 51.719 on 43 degrees of freedom
## AIC: 235.37
##
## Number of Fisher Scoring iterations: 1
##
##
## Theta: 4.01
## Std. Err.: 1.66
##
## 2 x log-likelihood: -229.37confint(mod3)## 2.5 % 97.5 %
## (Intercept) 3.04704214 4.753670460
## grain -0.01133949 -0.005064891Notice that the AIC for the negative binomial model is much lower than that for the (incorrect) poisson model. The residual deviance is now not much larger than the residual degrees of freedom. It is very important to include the overdispersion rather than use the assumption that the variance is equal to lambda that is built into poisson regression.
AIC(mod1)## [1] 251.3523AIC(mod3)## [1] 235.3695The variance of the negative binomial is
\(var=\mu+\frac{\mu^{2}}{\theta}\)
So theta controls the excess variability compared to Poisson. The smaller the value of theta the more skewed the distribution becomes.
par(mfcol=c(2,2))
hist(rnegbin(n=10000,mu=10,theta=100),main="Theta=100",col="grey")
hist(rnegbin(n=10000,mu=10,theta=10),main="Theta=10",col="grey")
hist(rnegbin(n=10000,mu=10,theta=1),main="Theta=1",col="grey")
hist(rnegbin(n=10000,mu=10,theta=0.1),main="Theta=0.1",col="grey")
Plotting the model produces a very similar result to that shown by the quasipoisson model.
glm3<-g0+geom_point()+geom_smooth(method="glm.nb", se=TRUE) +ggtitle("Negative binomial regression")
glm3
18.5 Comparing the results
library(ggplot2)
g0<-ggplot(d,aes(x=grain,y=richness))
glm1<-g0+geom_point()+stat_smooth(method="glm",method.args=list( family="poisson"), se=TRUE)
glm3<-glm1+geom_point()+geom_smooth(method="glm.nb", se=TRUE,color="red")
glm3
library(pscl)
modh<-hurdle(d$richness~grain,dist="negbin")
summary(modh)##
## Call:
## hurdle(formula = d$richness ~ grain, dist = "negbin")
##
## Pearson residuals:
## Min 1Q Median 3Q Max
## -1.5804 -0.8495 -0.1085 0.6236 2.0657
##
## Count model coefficients (truncated negbin with log link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.915924 0.458802 8.535 < 2e-16 ***
## grain -0.008220 0.001724 -4.767 1.87e-06 ***
## Log(theta) 1.510256 0.510987 2.956 0.00312 **
## Zero hurdle model coefficients (binomial with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 7.34139 3.39460 2.163 0.0306 *
## grain -0.01531 0.01005 -1.524 0.1275
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Theta: count = 4.5279
## Number of iterations in BFGS optimization: 13
## Log-likelihood: -114.5 on 5 DfAIC(modh)## [1] 238.9305AIC(mod3)## [1] 235.3695confint(modh)## 2.5 % 97.5 %
## count_(Intercept) 3.01668827 4.815159689
## count_grain -0.01159973 -0.004840422
## zero_(Intercept) 0.68811013 13.994679574
## zero_grain -0.03500187 0.004381010modzi <- zeroinfl(data=d,richness~grain,dist="negbin")
summary(modzi)##
## Call:
## zeroinfl(formula = richness ~ grain, data = d, dist = "negbin")
##
## Pearson residuals:
## Min 1Q Median 3Q Max
## -1.5740 -0.8408 -0.1085 0.6161 2.0427
##
## Count model coefficients (negbin with log link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.896314 0.446411 8.728 < 2e-16 ***
## grain -0.008132 0.001659 -4.902 9.49e-07 ***
## Log(theta) 1.514259 0.514694 2.942 0.00326 **
##
## Zero-inflation model coefficients (binomial with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -5.37854 11.19100 -0.481 0.631
## grain 0.00447 0.03878 0.115 0.908
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Theta = 4.5461
## Number of iterations in BFGS optimization: 35
## Log-likelihood: -114.6 on 5 DfAIC(modh)## [1] 238.9305AIC(modzi)## [1] 239.1852AIC(mod3)## [1] 235.369518.6 Models with binomial errors
The most commonly used GL is probably logistic regression. In this particular model the response can only take values of zero or one. Thus it is clear from the outset that errors cannot be normal. Let’s set up a simple simulated data set to show how this works. Imagine we are interested in mortality of pine trees following a ground fire. We might assume that the population of tree diameters are log normally distributed with a mean of twenty.
set.seed(1)
diam<-sort(rlnorm(500,mean=log(20),sd=0.5))
summary(diam)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.445 14.660 19.636 23.018 28.079 134.407hist(diam,col="grey",breaks=10)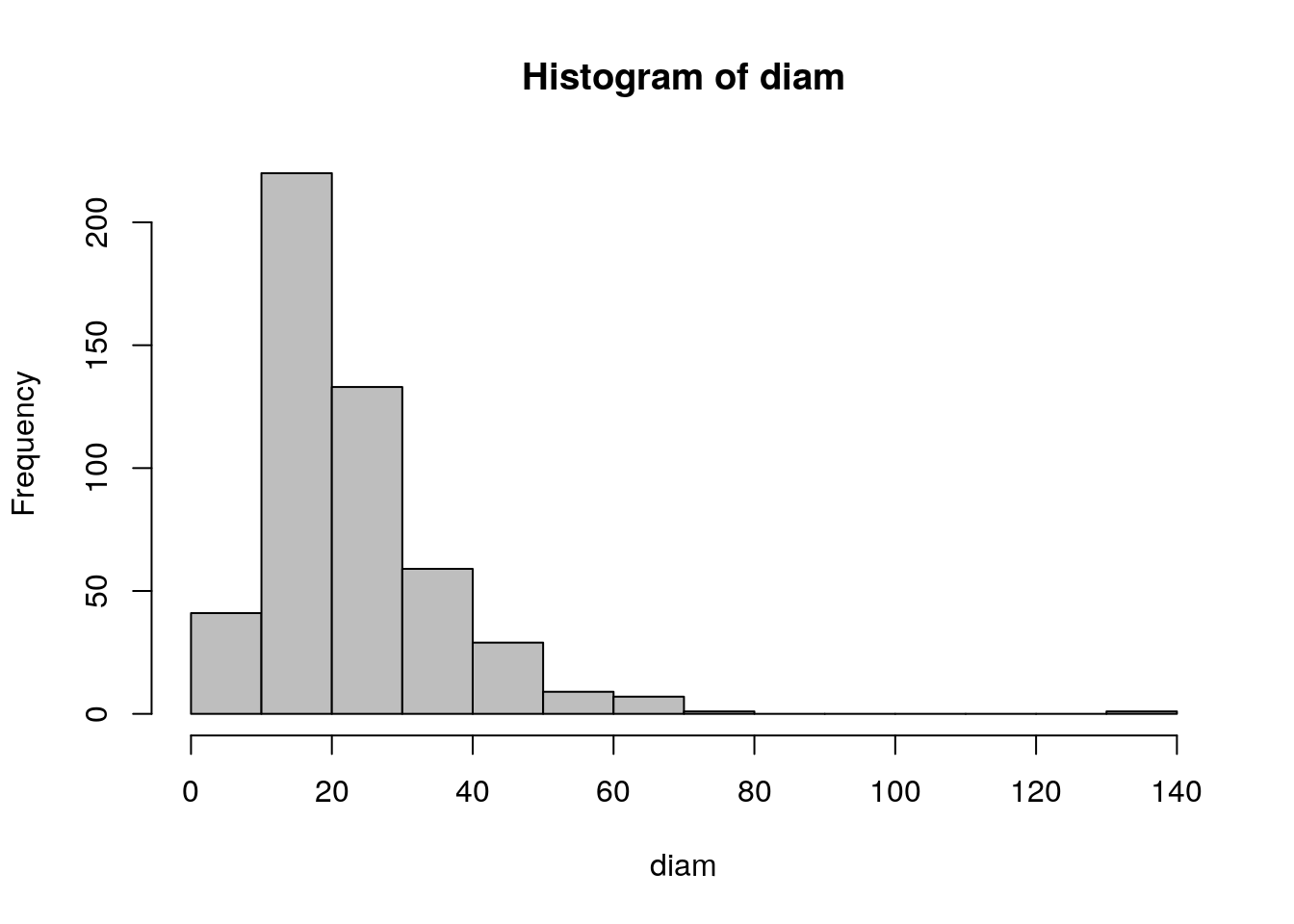
Let’s simulate some response data based on an extremely simple underlying pattern for tree mortality. We might assume that trees with diameters of over 40 cm have bark that has reached a thickness that prevents the tree being killed by the fire. We might also assume a simple linear relationship between diameter and mortality up to this threshold and build a simple rule based vector of the probability that a tree survives the fire as a function of its diameter.
p<-diam/50
p[p>1]<-1
plot(diam,p,ylab="Survival probability",xlab="Diameter",type="l",lwd=3)
Although we have a very simple underlying deterministic model, we will not see this directly when we collect data. Any individual tree will be either alive or dead. Thus our response will be zeros and ones. This is the problem that logistic regression deals with very neatly without the need to calculate proportions explicitly.
f<-function(x)rbinom(1,1,x)
response<-as.vector(sapply(p,f))
head(response)## [1] 0 0 0 1 0 0d<-data.frame(diam,response)
plot(diam,response)
lines(diam,p,lwd=3)
The task for the statistical model is to take this input and turn it back into a response model. Generalised linear models do this using a link function. In R it is very easy to specify the model. We simply write a model using the same syntax as for a linear model (one with gaussian errors) but we state the family of models we wish to use as binomial.
mod1<-glm(response~diam,family="binomial")
summary(mod1)##
## Call:
## glm(formula = response ~ diam, family = "binomial")
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.8202 -0.8891 -0.6053 1.0175 2.0428
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.60771 0.28033 -9.302 <2e-16 ***
## diam 0.10869 0.01217 8.929 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 688.91 on 499 degrees of freedom
## Residual deviance: 565.51 on 498 degrees of freedom
## AIC: 569.51
##
## Number of Fisher Scoring iterations: 5We can see that R does find a model that matches the underlying pattern very well by using the model for prediction. Again we visualise the model in order to understand it. This is always preferable to trying to understand a model from a table of numbers. Visualisation is particularly important for models with parameters expressed on a logit scale as this is not intuitive.
g0 <- ggplot(d,aes(x=diam,y=response))
g1<-g0+geom_point()+stat_smooth(method="glm",method.args=list(family="binomial"))
g1
If we wanted to check whether there was a response shape that differed from that assumed by the general linear model we could try a general additive model with a smoother.
library(mgcv)
g1<-g0+geom_point()+stat_smooth(method="gam",method.args=list(family="binomial"),formula=y~s(x))
g1
The curve is very similar. Note that as the smoother uses a form of “local” regression the confidence intervals expand in areas where there is little data.
In some cases the response would take a different form. This could happen if there were some optimum point at which some response occurred, for example the occurence of a species along an altitudinal gradient or shoreline. In this case the gam model would fit the data better than the linear model. We will look at how this can be tested formally later. A quick test is to calculate the AIC. If this is much lower for the gam it indicates that the gam may be a better fit.
glm_mod<-glm(data=d, response~diam, family=binomial)
gam_mod<-gam(data=d, response~s(diam), family=binomial)
AIC(glm_mod)## [1] 569.5078AIC(gam_mod)## [1] 566.4594In this case it is very slightly lower, but not enough to suggest the use of a gam.
18.7 The logit link function
The logit link function used in binomial glms makes the slope of the line quite difficult to understand. In most cases this doesn’t matter much, as you can concentrate on the sign and signficance of the parameter and show the line as a figure. However when analysing differences in response as a function of levels of a factor you do need to understand the logit link.
To illustrate let’s take a very simple example. Ten leaves are classified as being taken from shade or sun and classified for presence of rust.
library(purrr)
set.seed(1)
light<-rep(c("shade","sun"),each=10)
presence<-1*c(rbernoulli(10,p=0.5),rbernoulli(10,p=0.1))
d<-data.frame(light,presence)We can get a table of the results easily.
table(d)## presence
## light 0 1
## shade 4 6
## sun 9 1So 6 of the leaves in the shade had rust present and 4 did not. The odds of rust are therefore 6 to 4. Odds are used in the logit transform rather than simple proportions because odds can take values between 0 and infinity, while proportions are bounded to lie between zero and one. Taking the logarithm of the odds leads to an additive model.
There are two factor levels, shade and sun. The default reference when a model is fitted will be the factor that is first in alphabetical order, i.e. shade. So after fitting a model the intercept will be the log of the odds in the shade. The effect of light will be the log odds in the sun minus the log odds in the shade.
odds_shade<-6/4
odds_sun<-1/9
log(odds_shade)## [1] 0.4054651log(odds_sun)-log(odds_shade)## [1] -2.60269We can see that this coincides with the model output.
mod<-glm(data=d,presence~light,family="binomial")
summary(mod)##
## Call:
## glm(formula = presence ~ light, family = "binomial", data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.354 -0.459 -0.459 1.011 2.146
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.4055 0.6455 0.628 0.5299
## lightsun -2.6027 1.2360 -2.106 0.0352 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 25.898 on 19 degrees of freedom
## Residual deviance: 19.962 on 18 degrees of freedom
## AIC: 23.962
##
## Number of Fisher Scoring iterations: 4If the coeficients are exponentiated then the first coeficient represents the baseline odds and the second coeficient represesnts this value divided by the odds for the “treatment”. As binomial models are often used in epidemiology this explains why we could hear statements such as “eating processed meat increases the odds of contracting bowel cancer by a factor of 2”. This is a literal interpretation of the exponentiated coeficient.
exp(coef(mod))## (Intercept) lightsun
## 1.50000000 0.07407408odds_shade## [1] 1.5odds_sun/odds_shade## [1] 0.07407407To convert the odds into proportions divide the odds by 1 plus the odds.
odds_shade/(1+odds_shade)## [1] 0.6odds_sun/(1+odds_sun)## [1] 0.1So this gives the proportions as estimated by the model.
exp(coef(mod)[1])/(1+exp(coef(mod)[1]))## (Intercept)
## 0.6exp(coef(mod)[1] + coef(mod)[2])/(1+exp(coef(mod)[1] + coef(mod)[2]))## (Intercept)
## 0.118.8 Exercises
- GLMS can also be used when the explanatory variable is a factor. Here is a very simple data set that consists of counts of ragworm in two types of substrate, classified simply into mud and sand. Analyse the data using both a general linear model and a generalised linear model. Comment on the differences between the two aproaches.
d<-read.csv("/home/aqm/course/data/HedisteCounts.csv")- Binomial (prensence/absence) model
In some cases the actual numbers of organisms counted can be a poor choice of response variable. If organisms are highly aggregated then presence vs absence is a better choice. Reanalyse the ragworm data, this time using presence as the response.
d$pres<-1*(d$Count>0) ## This sets up a variable consisting of ones and zeros- Leafminers and leaf exposure to light
The number of leaf miners were counted on 200 leaves exposed to different levels of ambient light, measured as a percentage of full exposure.
Analyse these data using an appropriate GLM.
d<-read.csv("/home/aqm/course/data/leafminers.csv")plot(d)
library(plotly)
g0<-ggplot(d,aes(x=light,y=nminers))
glm1<-g0+geom_point()+stat_smooth(method="glm",method.args=list( family="poisson"), se=TRUE) +ggtitle("Poisson regression with log link function")
ggplotly(glm1)mod<-glm(data=d,nminers~light,family="poisson")
summary(mod)##
## Call:
## glm(formula = nminers ~ light, family = "poisson", data = d)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.0888 -1.7275 -1.1676 0.0864 5.9691
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -5.36721 1.09865 -4.885 1.03e-06 ***
## light 0.06610 0.01203 5.496 3.88e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 751.31 on 199 degrees of freedom
## Residual deviance: 720.43 on 198 degrees of freedom
## AIC: 1025.3
##
## Number of Fisher Scoring iterations: 6log(2)/coef(mod)[2]## light
## 10.48647